Del 5: Från modell till system – verktyg, agenter och rekursiva strukturer
I de fyra första delarna av vår artikelserie om hur LLMer fungerar har vi nu byggt upp en bild av vad en LLM är: en funktion f(·; θ) som tar en token-sekvens och producerar en sannolikhetsfördelning för nästa token. Begränsningarna följer ur att modellen saknar ett verifieringslager, persistent minne och tillgång till världen utanför kontexten.
Som vi var inne på i förra veckans nyhetsbrev är dessa utmaningar inte ’buggar’ utan en logisk följd av hur modellerna är byggda. För att ta oss an utmaningarna kan vi inte som Marc Andreessen säga åt modellen att ”hallucinera inte”.
Vi behöver bygga system runt modellen som får den att leverera det vi vill.
Kärnan är inte produkten
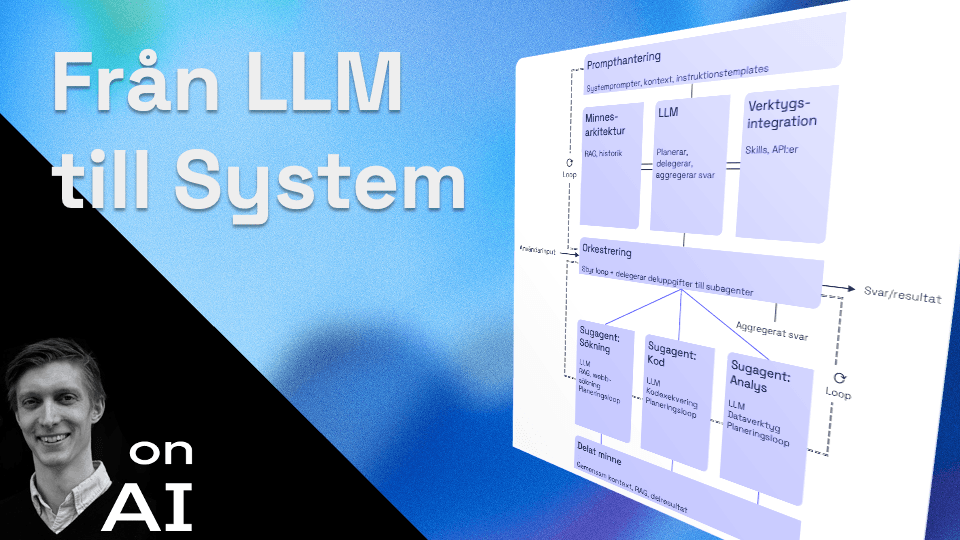
Precis som en bil är mycket mer än sin motor så är de flesta AI-produkter mycket mer än en språkmodell. De är konstruktioner där språkmodellen endast är en komponent bland flera. Fyra vanliga lager runt kärnan är prompthantering, verktygsintegration, minnesarkitektur och orkestrering.
Dessa lagers syfte är alltså att kompensera för vad modellen av strukturella skäl inte kan göra själv. Nedan tittar vi kort på vad respektive del har för roll och vilka utmaningar den möter.

Dessa lagers syfte är alltså att kompensera för vad modellen av strukturella skäl inte kan göra själv.
Nedan tittar vi kort på vad respektive del har för roll och vilka utmaningar den möter.
Orkestrering
Detta element fungerar som dirigenten, den tar emot prompten och styr sedan flödet mellan LLM, minne och verktyg. Det som ser ut som resonerande är normalt successiva loopar styrda från Orkestrering:
Generera -> Anropa -> Ta emot -> Generera vidare -> …
Verktygsintegration
En modell utan verktyg kan resonera om vad en databas förmodligen innehåller men den kan inte fråga den. Med möjligheten att anropa externa verktyg får systemet möjlighet att ställa frågan. Modellen genererar ett strukturerat anrop, systemet exekverar det mot ett externt API och returnerar resultatet som ny kontext.
Formellt utökas kontexten dynamiskt:
tₙ₊₁ := tool_result(f_tool(query(t₀…tₙ)))
Minnesarkitektur och Retrieval Augmented Generation (RAG)
Här har jag valt fokusera på RAG som adresserar utmaningen i att modellens tränade kunskap är statisk. Det här är ofta ett problem med ny aktuell information, exempelvis var ChatGPT-5.2 under en tid omedveten om sin egen existens utan hänvisade till ChatGTP-5.1 som den mest aktuella modellen.
Med RAG tillförs ett steg innan modellen erhåller prompten där en sökning görs i ett externt kunskapslager (vanligtvis ett vektordatalager där text indexerats som embeddings). De mest relevanta avsnitten identifieras via cosine similarity, ett sätt att mäta vilka vektorer som mest lika varandra genom att dividera två vektorers skalärprodukt med produkten av deras längder. En cosine similarity på 1 betyder att vektorerna pekar åt exakt samma håll (maximal likhet), 0 betyder ingen korrelation och -1 betyder att vektorerna pekar åt motsatt håll.
De mest relevanta avsnitten inkluderas sedan i kontexten tillsammans med prompten. Med andra ord fungerar det ungefär som att användaren med sin prompt hade skickat med ett antal sammanfattade relevanta källor.
RAG ger modellen tillgång till text den inte hade i θ, men ger den inte förmågan att resonera djupare om den. Kvaliteten begränsas av relevansen på det hämtade, hur väl det ryms i kontexten, och modellens förmåga att integrera det i sitt resonemang.
Agenter
En agent är ett system där modellen inte enbart svarar på given input utan styr sin egen sekvens av handlingar mot ett visst mål. Den generella loopen:
Mål → Plan → Aktion → Observation → Uppdaterad plan → …
Exempelvis en uppmaning att hitta ett ledigt bord för fyra på en fransk bistro med goda recensioner så nära Kungsholmstorg och så nära klockan 20:00 som möjligt. Här kan agenten initialt söka smalt och sedan, baserat på sökresultat, successivt justera sökområdet i dimensionerna tid, kvalitet (recensioner) och plats.

Användandet av agenter skapar alltså ett kraftfullare verktyg som är kapabelt att åta sig större uppgifter men också nya problem: felackumulering (tidiga fel driver systemet i fel riktning), kontexthantering (långa körningar genererar enorma kontexter vilket kostar) och stopp-problematik (en agent utan tydliga stoppvillkor kan hamna i loopar).
Multi-agent-system (rekursiva strukturer)
En rekursiv struktur betyder att ett system innehåller kopior av sig självt på olika nivåer. Komplexa uppgifter kan på det här sättet brytas ned rekursivt tills varje deluppgift är tillräckligt enkel för att en enskild agent ska klara den.
I ett multi-agent-system är det en orkestrerande agent som har rollen att bryta ned ett mål och delegera det till specialiserade agenter. Att strukturen är rekursiv innebär alltså att en agent kan anropa en annan som om det vore ett verktyg:
Orchestrator(mål) → Agent_A(deluppgift_1) + Agent_B(deluppgift_2) + Agent_B(deluppgift_3) → … → Slutsvar

Vad system löser och inte löser
Verktyg, RAG och agenter löser inte LLM-modellers begränsningar. De flyttar och mitigerar. Verktyg förflyttar verifieringsproblemet till det anropade systemet. RAG förflyttar kunskapsproblemet till söksystemet. Agentloopar förflyttar planeringen till modellen (och ökar samtidigt ytan för felansamling). Vi har alltså inte förändrat modellens natur. Kärnan förblir en sannolikhetsmaskin utan intern sanningskälla. Systemet omfördelar begränsningarna och mitigerar dem förhoppningsvis men eliminerar dem inte.
Som illustration på detta, anta att vi har en multi-agent bestående av Agent A som besvarar en fråga och Agent B som ska avgöra om svaret från Agent A är korrekt eller ej:
Fråga → Agent_A(svar) → Agent_B(bedömning av svar) → Slutsvar
Det här innebär att vi har fyra tänkbara utfall:
Agent_A(Rätt) + Agent B(Rätt) = Användare får rätt svar
Agent_A(Fel) + Agent B(Fel) = Användare får fel svar
Agent_A(Rätt) + Agent B(Fel) = Agent B underkänner ett korrekt svar
Agent_A(Fel) + Agent B(Rätt) = Agent B underkänner ett felaktigt svar
Med andra ord har vi minskat risken för felaktigt svar men samtidigt skapat utfall utan svar samt skapat risken att ett korrekt svar underkänns.
Andra problem
I exemplet ovan kanske Agent B skickar tillbaka frågan till Agent A när den anser svaret vara fel. I komplexa agentkedjor kan det här leda till en risk att systemet delegerar i oändlighet (avsaknad av Avbrottsvillkor). Fler LLM-anrop innebär också högre konsumtion av tokens (och pengar).
Fler nivåer gör det svårare för agentsystemet att hålla den ursprungliga uppgiften i fokus. I djupa agentkedjor leder det också till utmaningar med kausalitetsspårning och reproducerbarhet. Stokastisk sampling innebär att identisk input kan ge olika resultat.
Slutsatser
Sammanfattningsvis är principiella lösningar på tillförlitlighet i såväl i icke-rekursiva som i rekursiva system fortfarande ett öppet problem. Forskningen kring hur agentiska system byggs och trimmas går hela tiden framåt. Utöver att ta del av denna forskning (tex genom att läsa vårt nyhetsbrev) är det viktigt att minnas att LLM med sampling per definition inte är deterministiska.
Väsentliga frågor att ställa sig är:
- Vad vill jag uppnå?
- Vad behöver min modell ha tillgång till för att göra det så tillförlitligt som möjligt?
- Vilken är den högsta tillförlitligheten jag kan nå? Och
- Är den tillförlitligheten tillräcklig för det jag vill uppnå
Se där. Ett rekursivt resonemang som avslutning på den här artikelserien om LLMer. Har du inte läst de tidigare artiklarna så gör gärna det genom länkarna nedan.
Snart tillbaka med ett annat spännande och tekniskt perspektiv på AI.
Allt gott, Emil
If you are looking for another cog in the machinery...
There are plenty of other consulting firms that offer those. But if you value key people with stellar AI and development skills that will make a difference for your development team and your business. Then, leave it in our care!
DROP US AN EMAIL