Kontextlängd: en av de avgörande gränserna i dagens AI
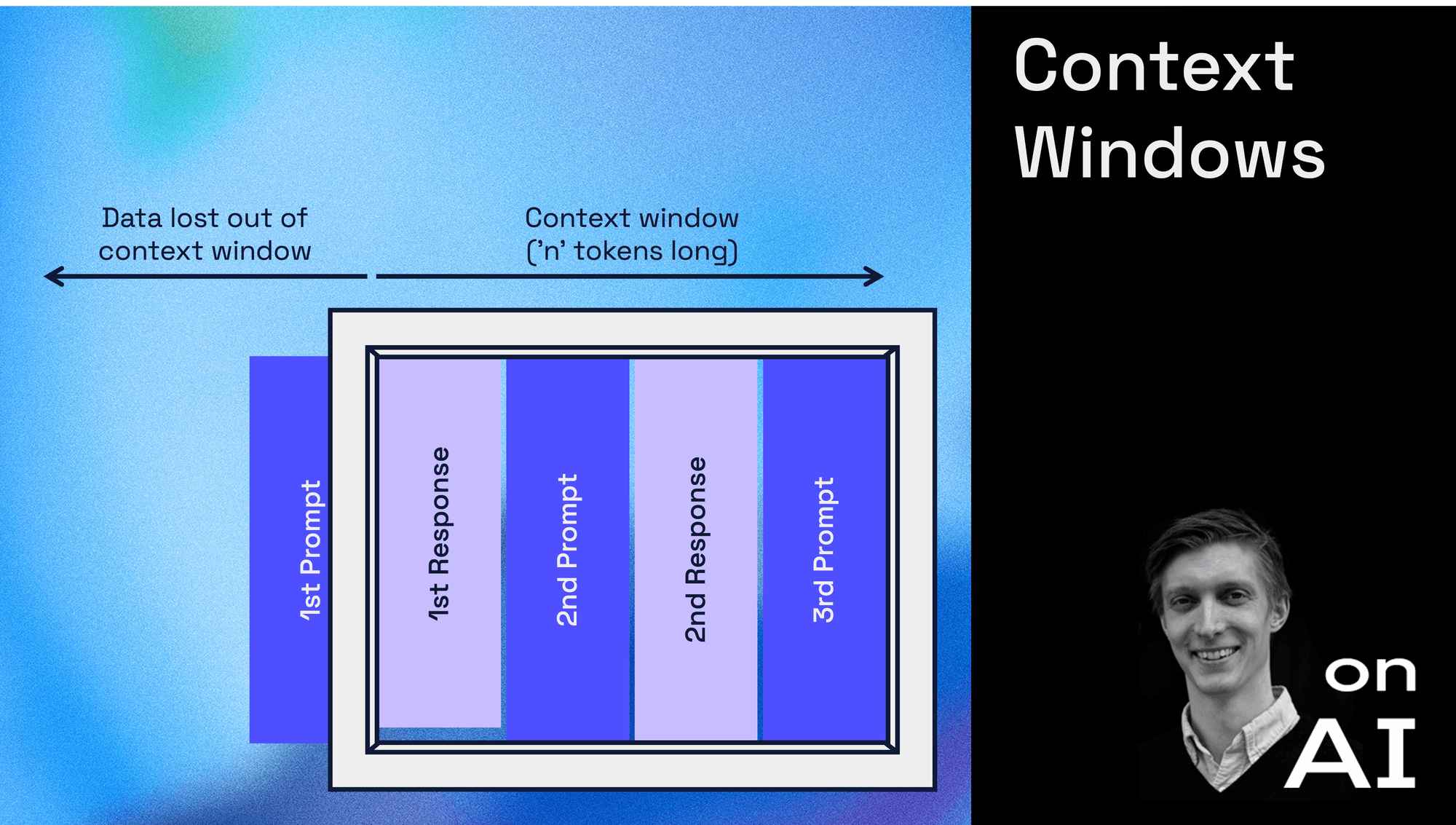
Kontextlängden är en av de parametrar som mest påverkar hur användbar en språkmodell är i praktiken. Det handlar om hur mycket text modellen kan ta hänsyn till samtidigt när den formulerar ett svar. I takt med att modellerna blivit kraftfullare har även förväntningarna ökat. Långa resonemang, stora dokument och komplexa arbetsflöden kräver ett stabilt och uthålligt arbetsminne.
För att förstå varför kontext är så centralt behöver man förstå hur modellerna faktiskt arbetar. När du skriver ett meddelande skickas inte bara din senaste fråga in i modellen. Hela konversationen paketeras om till tokens och matas in varje gång modellen ska generera ett svar. Det finns alltså inget separat minne som växer över tid. Modellen "minns" bara det som får plats i det aktuella fönstret och allt annat faller bort. Det är därför en modell ibland verkar tappa tråden trots att man själv upplever att man bara fortsätter där man slutade.
Vissa modeller deklarerar kontextfönster på hundratusentals tokens, men det betyder inte att de använder all information lika effektivt.
Det tekniska hindret ligger i hur uppmärksamhetsmekanismerna fungerar. Varje del av texten måste relateras till varje annan del, och kostnaden växer snabbt när sekvensen blir längre. Därför har mycket av forskningen riktats mot tekniker som gör att modellen läser mer selektivt eller komprimerar historiken på ett smartare sätt. Vissa modeller deklarerar kontextfönster på hundratusentals tokens, men det betyder inte att de använder all information lika effektivt. Fenomen som Lost in the Middle visar hur modeller ofta prioriterar början och slutet av en sekvens men ofta missar det däremellan.
I praktiken blir kontexten en flaskhals i många tillämpningar. Det gäller särskilt när man, som i min tidigare artikel om lokalt körbara modeller, använder komprimerade modeller på konsumenthårdvara. En mindre modell med bra kontexthantering kan ge bättre resultat än en större som tappar fokus. Därför kombineras modeller ofta med externa minnesstrukturer eller sammanfattningslager som hjälper dem att arbeta över större material än vad det interna fönstret tillåter. Det är detta som kallas RAG (Retrieval-Augmented Generation) och som är en teknik för att sammanfatta data från externa datakällor - något jag lär återkomma till i en framtida artikel.
Utvecklingen rör sig nu mot tre förbättringar. Arkitekturer som hanterar långa sekvenser effektivare. Externt minne som gör att modellerna kan arbeta över hela dataset utan att behöva bära allt i intern kontext. Och nya sätt att utvärdera modeller där man fokuserar på faktisk förmåga att använda lång kontext snarare än teoretisk maxlängd.
När vi följer modeller som snabbt närmar sig frontierprestanda även lokalt, något jag beskrev i samband med GPQA-Diamond, blir det tydligt att resonemangsförmågan inte enbart avgörs av parameterräkningen. Arbetsminnet och hur modellen använder det kan lika gärna visa sig vara nästa stora kvalitetslyft.
Det här är vårt sista nyhetsbrev i år. Har du missat några av de tidigare har du länkar nedan.
Önskar alla en god jul så är Emil on AI tillbaka i januari.
//Emil
If you are looking for another cog in the machinery...
There are plenty of other consulting firms that offer those. But if you value key people with stellar AI and development skills that will make a difference for your development team and your business. Then, leave it in our care!
DROP US AN EMAIL